
I’ve been following the shift toward Edge AI for a while. Not because I’m an AI maximalist, but because I’m interested in where the “math” meets the “machine”—specifically in autonomous hardware.
The promise is always the same: “Run LLMs on your device for privacy and speed.” But for a maritime drone in the middle of the Baltic Sea, it’s not about privacy; it’s about survival. If comms go down, you can’t ping a data center to ask if a ship on a 28-knot intercept course is a threat. You have a few watts of compute and about two seconds to decide.
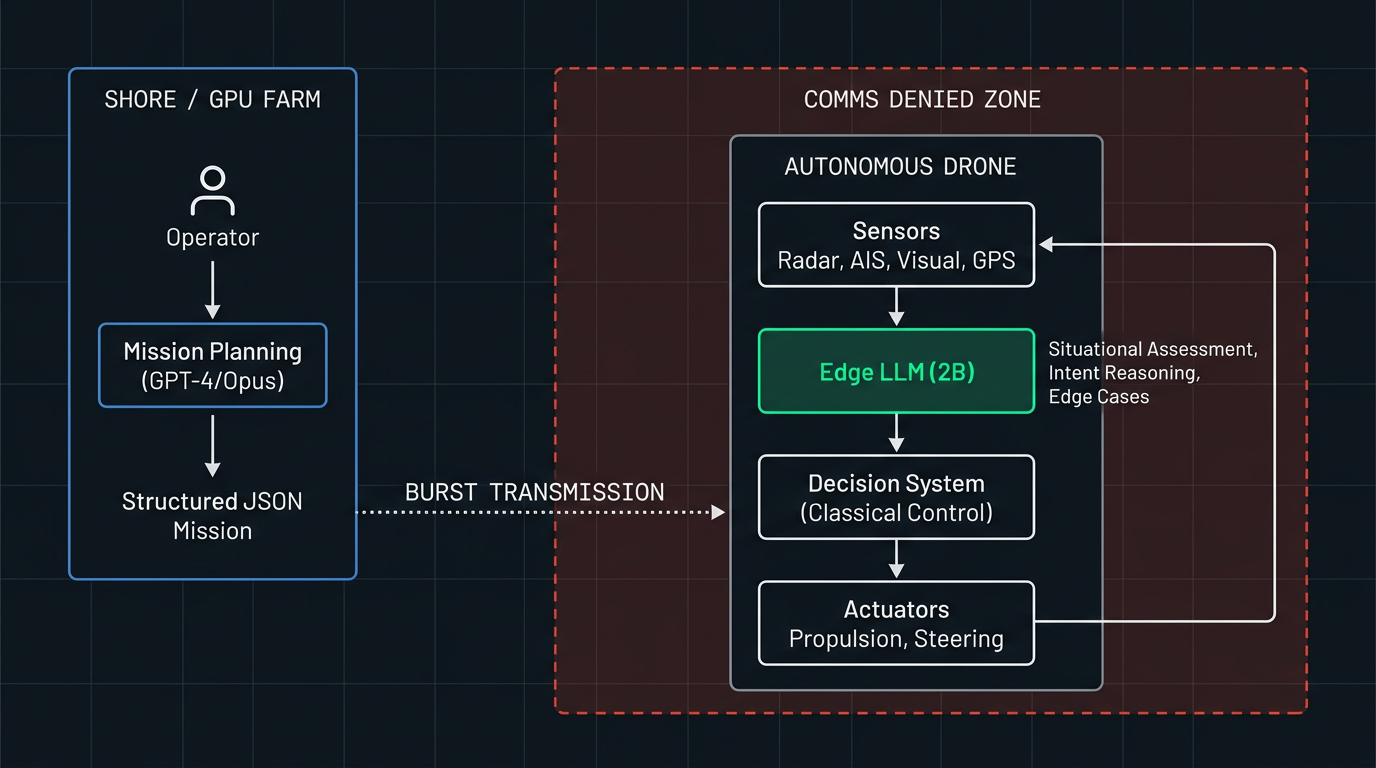
The edge LLM isn’t the autopilot—it’s the interpretation layer. Mission planning happens on shore with big models. Continuous situational assessment has to run locally.
I wanted to see if a 2B parameter model could actually handle that “tactical intuition” better than a few lines of Python code.
The Budget: €0.00
I decided to do this entirely on the free tier of Google Colab. I wanted to see how far curiosity could go without a credit card.
The original plan was to use the new Gemma 4 E4B, which is supposedly the sweet spot for edge devices. Reality hit immediately: the 16GB VRAM on the free T4 GPU is a hard ceiling. Trying to load and tune E4B in 16-bit pushed it straight into an Out-Of-Memory (OOM) error.
| Model | VRAM Required | Colab T4 (15GB) |
|---|---|---|
| Gemma 4 E4B (bf16) | ~16GB | ❌ OOM |
| Gemma 4 E2B (bf16) | ~5GB | ✅ Inference only |
| Gemma 2B (bf16) | ~5GB | ✅ Inference + LoRA |
The pivot:
- Drop down to Gemma 2B
- Batch size of 1
- Single epoch
- Save quantization for the deployment phase, not the training phase
It felt a bit like trying to tune an engine with a Swiss Army knife, but it kept the VRAM at a stable 5GB.
The Data: Distilling Reasoning from Claude
I didn’t have access to maritime tactical experts, so I built a synthetic data pipeline using Claude Opus as a “teacher model”—the Orca 2 approach.
The key insight: small models don’t just need labels, they need reasoning traces. Claude doesn’t just say “abort”—it explains why:
{
"scenario": {
"mission_type": "transit",
"vessels": [{
"bearing": 315, "distance": 1.2, "speed": 32,
"vessel_type": "military", "ais_active": false,
"visual_description": "grey hull, radar arrays"
}],
"weather": "rough", "comms_status": "degraded"
},
"decision": {
"threat_level": "critical",
"action": "abort",
"reasoning": "Military vessel on direct collision course at high speed,
no AIS, degraded comms. Cannot verify friendly status.
Mission abort required for survival.",
"confidence": 0.92
}
}Final dataset: 300 scenarios with this distribution:
| Threat Level | % | Action | % |
|---|---|---|---|
| none | 28% | continue | 29% |
| low | 20% | monitor | 33% |
| medium | 17% | evade | 24% |
| high | 21% | alert | 9% |
| critical | 14% | abort | 5% |
The imbalance toward “monitor” reflects reality—most situations aren’t emergencies. But it also foreshadows the mode collapse problem.
Rules vs. Nuance
I wrote a rule-based script as a baseline. It’s effective but blunt.
- The Rule: “If distance < 1nm and AIS is off, then Abort.”
- The Problem: If a ship is 1.1nm away but moving at 40 knots, the rule says “Everything is fine.”
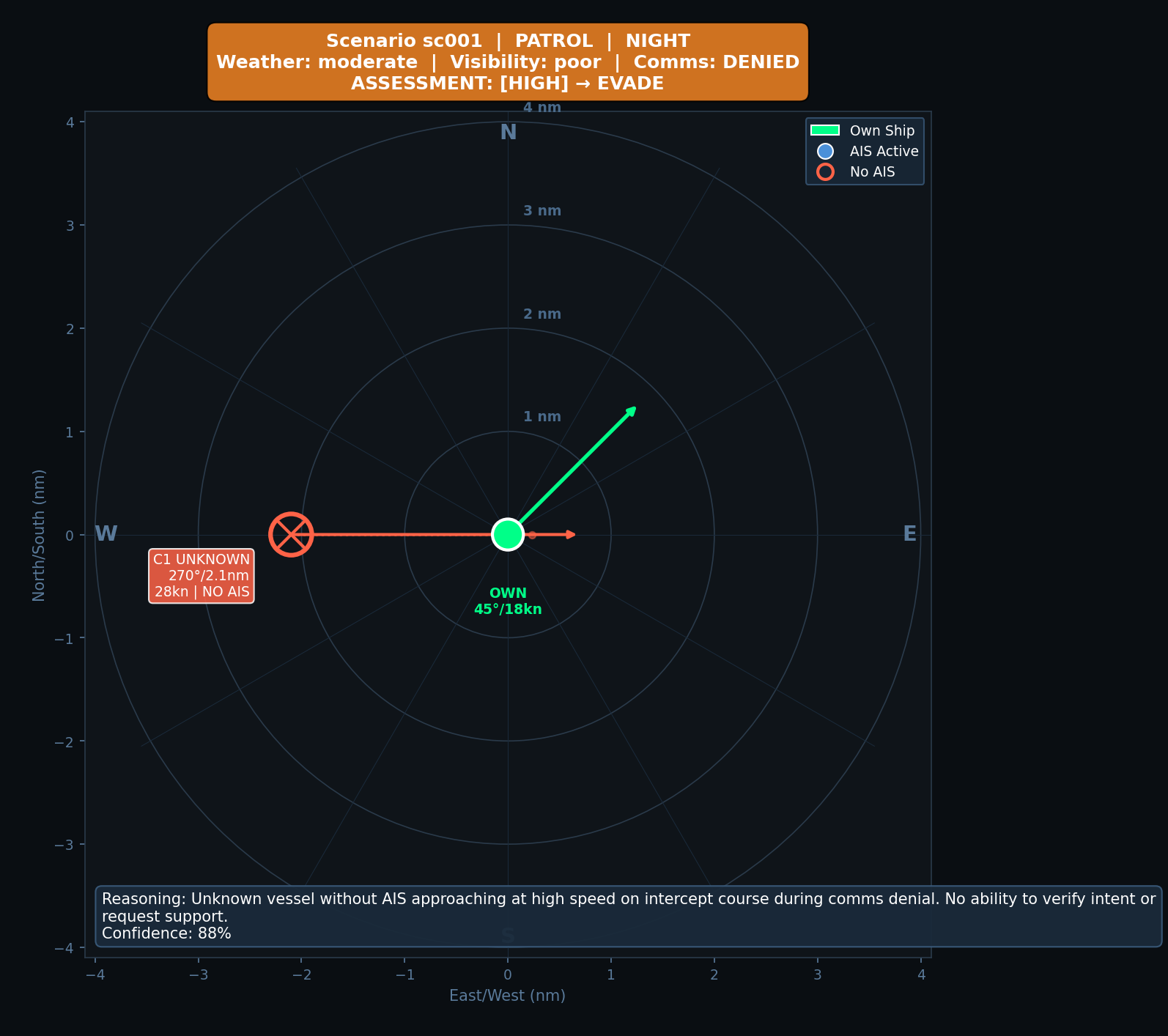
Example scenario: Unknown vessel (red) approaching on intercept course. No AIS, no lights. The rule checks distance. A human checks intent.
LLMs should, in theory, handle this “middle ground” nuance—the cases where context matters more than thresholds.
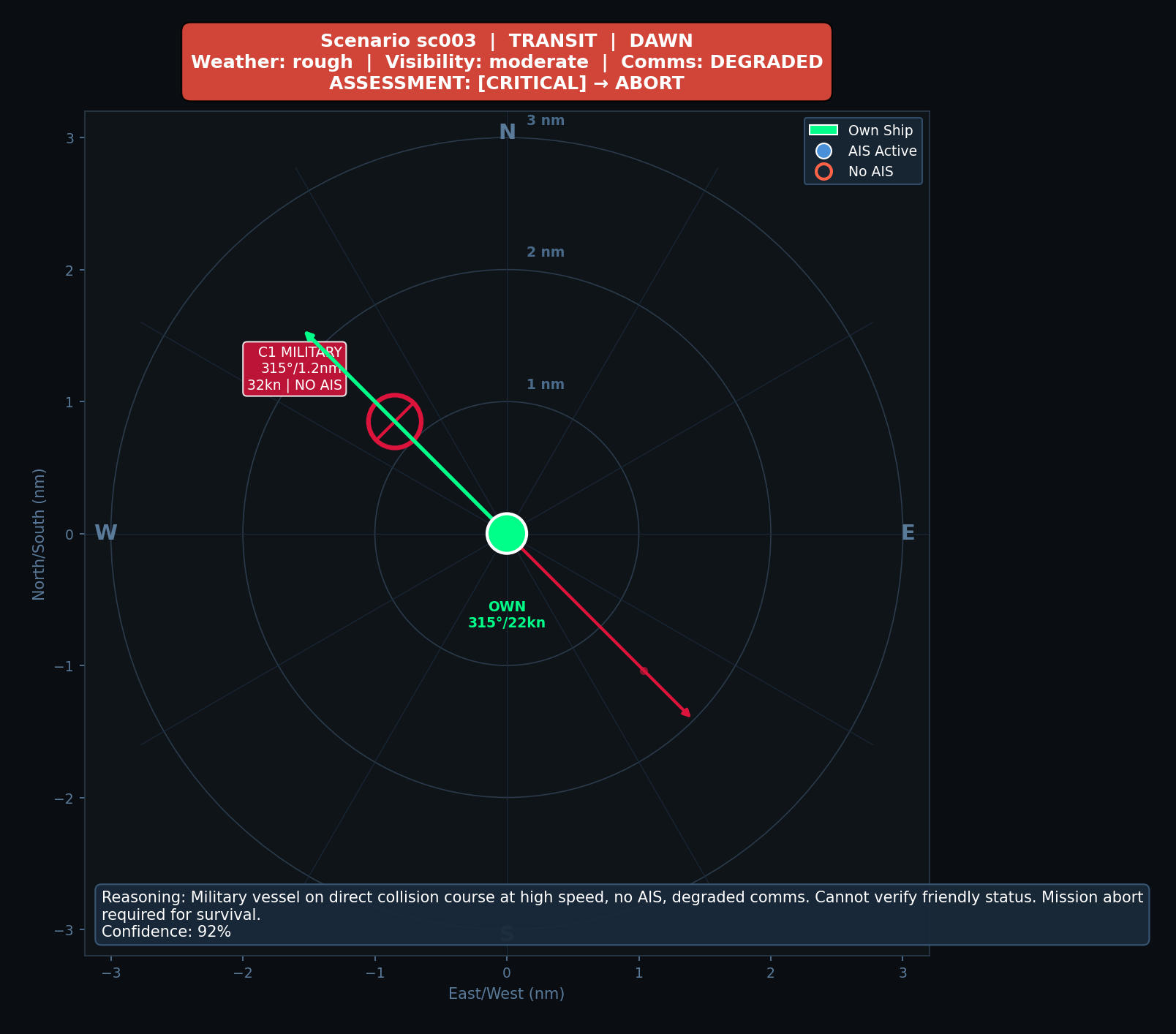
A “critical” scenario: Military vessel at 1.2nm, 32 knots, no AIS, degraded comms. Rules get this right. But what about the edge cases?
The Results (The Rules Won)
I ran the eval, and the rule-based system beat every model I tested.
| Model | Accuracy |
|---|---|
| Rule-based Baseline | 36.0% |
| Gemma 4 E2B (Raw) | 22.7% |
| Gemma 2B (Raw) | 18.3% |
| Gemma 2B (LoRA, 1 epoch) | 20.0% |
Seeing a 2B model get outperformed by a script I wrote in 20 minutes was a reality check. The raw models were plagued by “mode collapse”—they’ve been RLHF’d to be so safe and polite that they default to “Monitor” (the maritime version of “I can’t help with that”) even when a collision is imminent.
However, the fine-tuning worked.
Look at the progression: Gemma 4 E2B (2.1B params) hits 22.7% out of the box. Gemma 2B starts at 18.3%—but after a single epoch of LoRA, it climbs to 20.0%.
That’s a 4.4 percentage point gap closed with one pass over 240 examples on a free GPU.
The larger model has more “world knowledge” baked in, so it starts higher. But the smaller model is learnable—it responds to domain-specific training. With more epochs, higher LoRA rank, and better data, that 2B model could potentially match or beat the E2B baseline. And it would still fit on a Raspberry Pi.
Lessons from the T4 Trenches
Hardware is the real filter. In 2026, the gap isn’t just in the models; it’s in the memory. You’re constantly trading off precision for the ability to actually run a training loop.
Hybrid is the way. You don’t need an LLM to tell you that a ship 100 meters away is a threat. You need the LLM to interpret the intent of three ships moving in a pincer formation. The best system is likely a rule-based “safety rail” with an LLM “advisor.”
The open source vibe. It’s incredible that we can do this for free. Even if the results weren’t a “win” for the LLM, the fact that I can iterate on tactical hardware reasoning from a browser tab is fascinating.
The “Next Big Thing” might not be here yet, but the tools are. I’m going to keep exploring the intersection of hardware and these tiny models—next time, maybe with a bit more VRAM.
Code & Data: github.com/hanng00/llm-edge-maritime